Dual-Scale Data Charts
Team
Motivation
Data charts such as line charts, bar charts, and scatter plots are arguably among the most common data representations used today. They have found widespread adoption in a variety of disciplines and are also frequently used to communicate information to the public. One of the problems of data charts in practice is that they become difficult to read when the amount of data goes beyond the available display resolution.
When the density of data points and/or their degree of interest is not uniform - e.g., time series with dense event clusters and large empty spaces in-between - one way to overcome visual resolution limitations is to use more than one scale (number of data units per display unit) in the same chart. Visually, this leads to charts where scale changes between regions with relatively high magnification, as well as regions where contextual data is displayed in a more condensed fashion.
Many different ways exist to visually integrate these different scales. Popular approaches include cut-out charts and superimposed charts.
On this website we show a number of different examples to create dual-scale charts.
Most charts were created with ProtoVis a free open-source toolkit for visualization.
Further Information
We ran a user study comparing the different chart types listed below. For details, please have a look at our scientific paper.
In a very short summary, we would recommend to use dual-scale charts in the order listed below. This recommendation takes several factors into account including the effectiveness of these charts in our perceptual experiment and the ease of creating the charts:
- Cutout Chart
- Broken Chart
- Lens Chart
- Superimposed Chart (actually we don't recommend to use this chart at all - but if you absolutely must...)
Viewing Disclaimer
Internet Explorer does not support viewing the visualizations on this page (because it does not support the HTML5 Canvas element.
Please use a different browser, Firefox, Chrome, Opera, or Safari should all work.
We have not had the time to provide images as a replacement for people viewing this page with Internet Explorer (but may do so in the future).
Setting the Scene - The Regular Data Chart
About this Chart
The data for this chart was taken from the Time Series Data Library.
We are looking at dataset ca051 which contains tree ring widths (one per year) from a limber pine tree in California.
The tree was very old: the data ranges from 42BC to 1970AD.
The x-axis labels show the age of the tree.
Let's assume we're interested in the overall pattern of tree ring growth over the years.
We have a particular interest in the first 100 years but still want to display the remainder of the data to put everything in context. In the regular chart above the first 100 years are not emphasized - rather, we see everything at the same scale.
In the following example we will use dual-scale charts to emphasize the first part of the data within the same data chart.
In case you are interested in trying out the examples yourself, here is the data file (just look at the page source to see how the code was integrated and the data was loaded).
A cut-out chart with a context region on the top and a focus region on the bottom.
The ProtoVis source code
About this Chart
This type of chart is frequently used to display data along timelines. The top part of the chart shows the whole dataset and highlights the focus while the bottom shows the focus extended to the width of the display area.
This chart has a good visual resolution along the x-axis, with the focus part having the same magnification as the superimposed chart (and better than all other charts) and the context part having the same magnification as the regular chart (better than all other charts except the superimposed one). Along the y-axis, however, the chart has a smaller magnification factor for the same footprint. In the example above both focus and context have the same height as in the other charts but that means that the whole chart is twice as high (plus the space in the middle). That's why typically this chart is drawn more like seen below.
Variations
Typically you will see this chart drawn with one part of the data being compressed in y. This helps to reduce the overall chart size but creates problems when you want to relate the data in the focus regions with that outside since now not only the x-scale is different but the y-scale as well.
Below is a common example of such a chart. It's pretty obvious that relating data between focus and context is much more difficult than in the example on top.
A cutout chart with the context compressed in y to make the overall chart height smaller.
The ProtoVis source code
If we want to keep the chart the same size as in the original above (and the other examples below) we have to reduce both focus and context in y. Here is an example of what this would look like:
A cutout chart that has the same overall size as the regular chart above but now both focus and context region are more compressed in y than in the original example.
The ProtoVis source code
A broken chart with a visible gap marking the change in scale from left to right.
The ProtoVis source code
About this Chart
We call this chart a broken chart since it is basically a regular chart broken into two parts.
The visible gap in the middle was promoted by Cleveland to ensure that the change in the ruler (the x-axis ruler) is clearly noticed by the viewer.
One disadvantage of this chart is that - while the change in scale is clearly noticed - the two parts may look like they are actually showing two different datasets.
In our user study people performed quite well with this chart. Note that this chart is very easy to create with almost any tool by just placing two separate charts side-by-side.
Variations
Of course one could also create this chart without any gap in the middle. However, in case the data itself doesn't as clearly reveal the change in scale - as in our case - this may be easily overlooked.
A broken chart with no visible gap marking the change in scale from left to right.
The ProtoVis source code
The idea for the lens chart was inspired from the way that focus+context lenses can be used on different kinds data, e.g. maps.
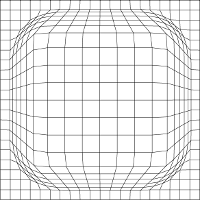
The question is whether and how such a lens distortion can be usefully applied to a chart. This chart is not commonly part of any charting packages because it is quite tricky to implement correctly.
We found that people were on average as effective with this chart as with the broken chart (which is really easy to implement). Yet, the LensChart has a nice visual integration of the data. Below you will find some information on why this chart is a bit tricky to implement.
About this Chart
As you can see in the image above, the distortion is very effective when gridlines are placed to indicate the position of the lens on the image. For charts, this grid would be represented by the gridlines, yet, the story is not as simple. Let's see what happens when we apply a lens to the data we have been looking at so far.
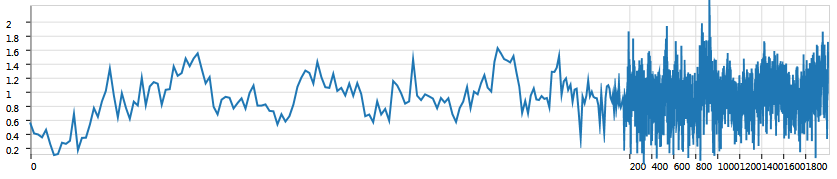
Well, this is not a very good lens chart as there is no good drop-off from the focus region on the left to the context on the right. This happens because there is actually quite a huge magnification on this chart enlarging the first 100 values to half the width of the chart and the next 100 to half of the remaining space, squeezing approximately 1800 data values into a quarter of the chart area. It doesn't look very good also, because the gridlines were determined from the whole data space, trying to fit about 10 gridlines for 2000 data values, meaning that there will be one gridline every 200 values.
We could tweak this and display a lot more gridlines:
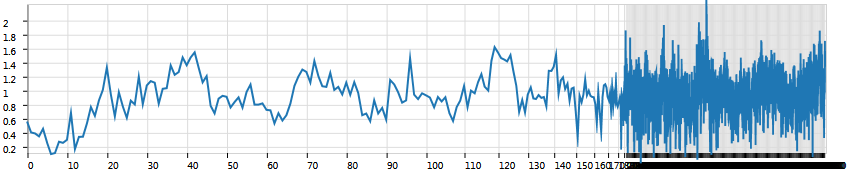
Now the lens effect is visible but we have a problem with gridline density in the context region. Here we need less gridlines but less gridlines mean that the lens effect will show no smooth integration into the context.
For other focus-sizes the LensChart can, however, look nice quite easily without having to tweak the gridline code. For example, by moving about 300 data points into the focus, the original gridline-spacing of 200 data points will already show the lens effect - admittedly a little.
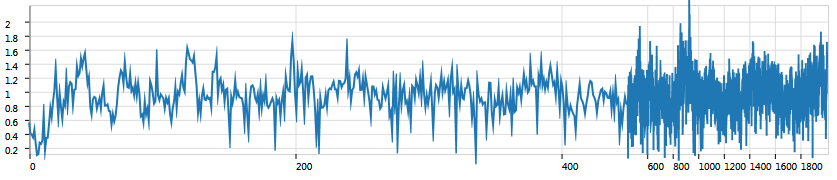
Due to these difficulties, the LensChart requires a dedicated implementation of its own. Our paper will give you some information on how we implemented the chart but we do not have working ProtoVis code which will work for all chart cases (hence above you only see screenshots from our original WPF implementation).
Variations
It is interesting to consider what the Lens Chart would look like if one wants to put the focus region in the middle of the chart. This again, is tricky to implement. When moving a fisheye lens on map data, for example, one can freely change the bounds of the data. Yet, if one wants to keep the chart area fixed, a lens in the middle of the chart means that the two context regions are fully defined in magnification and will not be the same unless the focus is directly over the middle of the dataset.
A superimposed chart where both the region of interest and the contextual data are drawn on top of each other The first 100 years are drawn in red on top according to the bottom ruler and the remaining years in blue according to the top ruler.
The ProtoVis source code
About this Chart
This is a very problematic chart as it is very difficult to read.
We haven't added a legend so you need to know that the orange line is drawn according to the bottom scale and the blue lines according to the top scale.
You could probably deduce this from the previous charts in this example but if you only had this chart you would have a problem.
Having to differentiate the two parts of the dataset also means that a specific visual variable (in this case color - but you could also use pattern, for example) cannote easily be used to encode other parts of the data (e.g. very high or very low values).
Several design decisions went into creating this chart. One is that the y-axis on both charts shows the same data range.
Often these charts are also drawn with a different y-scale making the data even more confusing.
Another problem this chart has is that it no longer has gridlines crossing the chart area but instead relies on tickmarks only.
Why? Well in this case the ranges are so that the gridlines would not fall onto each other neatly but would be very unevenly spaced across the chart as you can see in the example below.
A superimposed chart with gridlines turned on both for the top and the bottom scale. This creates somewhat of a mess.
While the chart is quite confusing, it also has one main advantage: both parts of the data are displayed maximally wide
(assuming we have a given width for all our chart options).
Yet, in our user study people performed very badly with this chart - despite the fact that we trained them specifically on how to read it.
Note that this chart is very easy to create in Microsoft Excel and, thus, it is relatively common.
Based on our study we recommend:
do not use this chart!
Variations
There are many variations of this chart online. Below you see an image of one variation created with Microsoft Excel. Here the x-axis is shared among the two parts of the data and the y-axes are different (Excel doesn't let you share the y-axis and split the x-axis for some reason).
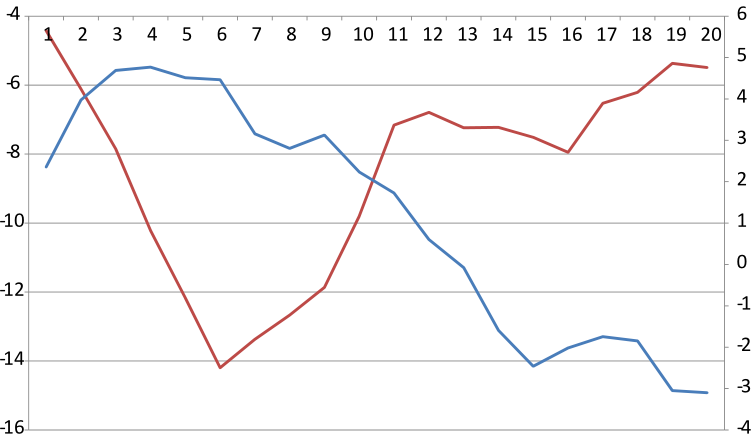
A superimposed chart created with Microsoft Excel.
Further Information
Further information on these charts can be found in our IEEE InfoVis publication:
Petra Isenberg, Anastasia Bezerianos, and Pierre Dragicevic and Jean-Daniel Fekete (2011)
A Study on Dual-Scale Data Charts. IEEE Transactions on Visualization and Computer Graphics (Proceedings Visualization / Information Visualization 2011), 17(12), December 2011
(pdf).